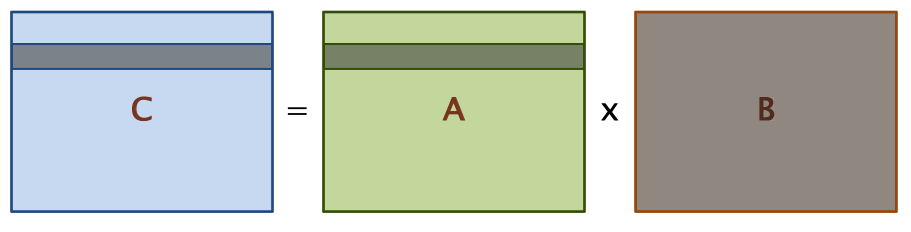
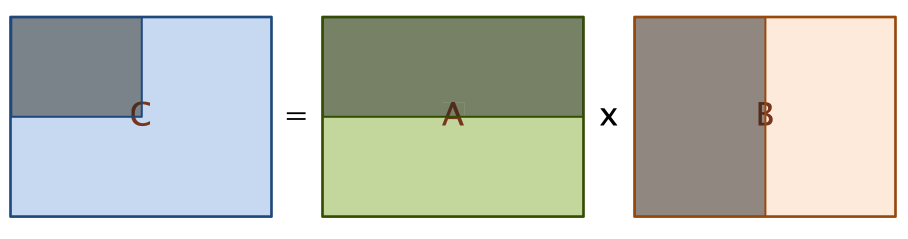
- 왜 필요할까?
- 추상화
- 레퍼런스 카운팅
- 트레이싱 컬렉션
- 세대 별 컬렉션 (Generational Collection)
- 고급 기능들
- 재밌는 사실들
모든 프로그램은 메모리가 필요하다.
자동으로 관리되는 스택은 크기가 제한적이다. 보통 윈도우는 1MB이고 리눅스는 8MB다. 튜닝으로 이 값을 조절할 순 있겠지만 그래도 한계가 있다. 더 큰 크기의 계산을 하려면 스택을 벗어나 힙 메모리가 필요하다. 프로그램은 커널에게 부탁해서 힙 메모리를 얻을 수 있다. 힙 메모리를 가지고 필요한 계산을 끝내고 나면 다 쓴 메모리는 다시 커널에게 돌려줘야 한다. 가상 메모리도 물리 메모리도 모두 유한한 자원이기 때문이다. 제때 안돌려주고 계속 메모리를 얻기만 하면 계속된 페이징, 스와핑, 페이지 폴트, 쓰레싱(Thrashing) 등의 이유로 성능이 계속 곤두박질치다가 결국 커널은 패닉에 빠질 것이다.
그래서 보통은 프로그래머가 직접 메모리를 관리하는 코드를 작성한다. 필요한 만큼 커널에게 할당받아서 쓰고 (Memory Allocation, 메모리 할당), 다 쓰고 나면 다시 커널에게 돌려준다 (Free, 메모리 해제). 이 짝을 맞추는 게 기본이다. 그러나 프로젝트의 요구사항이 복잡해지고 프로그래밍 언어의 고급 기능이 많아질수록 (예: 예외 처리, 코루틴), 이 짝을 맞추는 일이 어려워진다. 무엇보다 사람은 실수를 저지른다. 이미 돌려줘서 유효하지 않은 메모리를 사용해버리거나 (Use After Free), 까먹고 돌려주지 않은 채로 계속 있거나 (Memory Leak), 같은 메모리를 여러 번 돌려주는 (Double Free) 등의 실수는 너무도 흔해서 각각에 이름이 붙을 정도다. 그리고 이런 오류는 적어도 프로그램의 성능을 깎아먹거나, 치명적인 보안 취약점을 노출시키거나, 프로그램을 죽여버린다.
그래서 자동으로 메모리를 관리하는 방법이 연구되기 시작한다. 최초의 자동 메모리 관리 방법은 1959년에 Lisp 프로그래밍 언어에 도입되었다. Lisp의 창시자이자 인공지능 연구자 존 매카시 님의 관련 논문의 27페이지에는 트레이싱 컬렉션(Tracing Collection)에 대한 기초적인 아이디어, 즉 프로그램의 어떤 부분에서도 찾을 수 없는(닿을 수 없는) 데이터는 버려진 것으로 간주하고 나중에 재활용하는 방법을 설명하고 있다.
… Such a register may be considered abandoned by the program because its contents can no longer be found by any possible program; hence its contents are no longer of interest, and so we would like to have it back on the free-storage list. …
뱀발로 7번 각주가 꽤 재밌는데:
We already called this process “garbage collection”, but I guess I chickened out of using it in the paper - or else the Research Laboratory of Electronics grammar ladies wouldn’t let me.
논문에서는 이렇게 각주에 딱 한번만 등장한 “가비지 컬렉션”이라는 이름이 지금은 표준적인 이름으로 널리 쓰이고 있다는 사실이 아이러니하다.
왜 필요할까?
“애초에 가비지 컬렉션이 왜 필요함? 처음부터 메모리 이슈 없게 잘 짜면 되는 거 아님?” 이라고 생각할 수 있다. 과거의 나도 그랬다. 하지만, 비단 가비지 컬렉션이 아니더라도, 메모리 관리를 위한 다양한 방법론이 여전히 연구 되고 있는 데에는 다 이유가 있다.
역사가 말해줌
먼저 과거를 한번 살펴보자. 최초의 가비지 컬렉션이 Lisp 언어에 도입된 이유 중 하나는, 당시 메이저 언어 였던 ALGOL 언어에서 댕글링 포인터 문제, 그러니까 쓰던 메모리를 이미 해제했는데 그걸 모른채로 프로그램의 다른 부분에서 해제된 메모리 주소를 계속 갖고 있다가 사용해버리는 심각한 버그가 큰 이슈였다 (Use After Free). 그 당시 프로그래머라면 정말 똑똑한 소수의 선택된 사람들일텐데, 그런 친구들에게도 메모리를 관리하는 일은 쉽지 않았던 것이다.
근데 이건 지금도 해결되지 않았고, 오히려 인터넷이 발전하면서 더 심각해졌다. Use After Free 버그는 이제 단순히 프로그램을 죽이는 데서 그치지 않고 프로그램의 보안 취약점이 되어 실제적인 위협이 되어버렸다. 마이크로소프트의 한 조사에 따르면 매년 CVE (공개적으로 알려진 보안 취약점에 아이디를 붙이는 시스템) 의 약 70%가 메모리 안전성 문제라고 한다. 구글에서도 비슷한 결과를 발표한 적이 있는데, 크롬의 심각한 보안 관련 버그 중 70%가 메모리 관련 오류, 그 중 절반이 Use After Free였다고 한다.
1960년대에 발견된 문제가 2020년대에도 여전히 보안 취약점의 대다수를 차지한다는 사실은 “사람이 직접” 메모리를 관리하는 것이 얼마나 어려운지를 보여준다.
문제의 난이도
“메모리 이슈 없게 잘 짜면 되는 거 아님?”이 얼마나 어려운지를 보여주는 또 다른 명확한 근거는 바로 이 문제 자체의 본질적인 고난도이다. 메모리 오류의 대부분은 결국 커널로부터 힙 메모리를 할당 받아서 (malloc) 쓴 다음에 이걸 적절한 타이밍에 돌려줘야 (free) 하는 이 타이밍이 어긋나서 발생하는 것이다. 그런데 이렇게 메모리를 할당하고 돌려주는 작업이 필요한 시점을 정확하게 예측하는 것은 이론적으로 불가능하다. 다시 말해, “여기서 할당되어서 사용되던 메모리가 코드의 여기에서 딱 사용이 끝날테니 여기다가 free를 넣으면 되겠다” 라는 분석이 원천적으로 불가능하다. 왜냐하면 코드만 가지고는 할당된 메모리의 수명을 알아내는 알고리즘은 만들 수 없기 때문이다 (Undecidable).1 그렇다고 프로그램이 끝나는 시점에 한꺼번에 메모리를 돌려줘버리면 애초에 메모리를 관리하려는 의미가 없지. 개인적으로 객체의 메모리 수명주기는 요구사항에 가깝지 않나 하는 생각이 든다.
좀더 쉬운 문제로, “어떤 객체의 메모리는 크기는 이정도이고 수명은 이정도다”라는 정보가 미리 알려져 있을 때 모든 객체들의 할당과 해제 시점을 잘 배치해서 메모리 사용량을 최소화 하도록 하는 동적 스토리지 할당 (Dynamic Storage Allocation, DSA) 문제를 한번 생각해보자. 그런데 이 문제는 NP-Complete 임이 증명되어 있다. 즉, 메모리를 잘 배치해서 최소한의 메모리만 사용하도록 계산하는 알고리즘이 있긴 있는데, 언제 끝날지 모른다. 다시 말해 메모리의 생명주기(Lifetime)가 “이미 알려져 있는” 경우에도 최적의 배치를 찾는 것이 무척 어렵다는 말이다.
정리하면, 메모리를 할당하고 해제하는 작업을 정확하게 계산하는 것은 이론적으로 불가능하고, 그것보다 더 쉬운 문제의 경우에도 무척 어렵다.
인지적 부하
내가 중요하게 생각하는 것 중 하나는 바로 인지적인 부하이다 (Cognitive Load). 현대의 대규모 소프트웨어를 개발하는 일은 어렵다. 설령 작은 규모를 혼자서 만들더라도 현재의 나와 미래의 나는 다른 사람이다. 코드는 쓰이는 것보다 훨씬 더 많이 읽힌다. 관련해서 많은 격언들이 있다2. 아무튼, 어떤 코드 베이스를 이해하는 작업은 어렵다.
예를 들어, 어떤 프로젝트의 코드 한 줄을 이해하고 싶다고 하자. 만약 이 코드가 속한 함수나 파일을 넘어서, 코드 베이스 전체, 심지어는 프로젝트가 의존하고 있는 패키지를 다 따라가서 모든 것들을 고려해야 한다면, 이는 결코 쉬운 작업이 아니다 (Global Reasoning). 반면에, 그 코드의 근처의 로직만 살펴봐도 충분하다면, 이 작업은 한결 수월해질 것이다 (Local Reasoning).
이렇게 근처 코드만 봐도 로직을 이해할 수 있는, 진정한 의미의 “모듈화된 프로그래밍 (Modular Programming)”을 위해서는 가비지 컬렉션이 필요하다. 모듈 사이에 의존성이 생기는 것을 막을 수는 없다. 하지만 모듈이 계산을 위해 메모리 할당을 필요로 할 때 이 메모리의 소유권에 대한 분쟁이 발생한다 (Ownership). 특히 모듈 객체의 생명주기는 전역적인 속성이다. 예를 들어, 모듈 A가 할당하는 어떤 객체를 모듈 B와 C가 공유할 때, 이 객체가 언제 해제되어야 하는지를 알기 위해서는 이 세 모듈을 모두 추적해야만 한다. 그런데 이렇게 모듈이 사용하는 메모리도 생각해야 한다면 핵심 로직에 대한 이해가 급격하게 어려워진다. 안그래도 어려워 죽겠는데 메모리 관리까지 해야 한다니.
그 외에도 모듈 객체의 메모리를 안전하고 정확하게 해제하기 위한 다양한 추가 구현이 런타임에 상당한 비용을 초래할 수도 있다. 멀티 쓰레드 어플리케이션이면 동기화도 고려해야 한다. 아무튼 간에 복잡해진다.
결국 언어 설계는 안전성, 표현력, 성능, 사용성 사이의 트레이드오프를 고려해야 한다. 가비지 컬렉션은 약간의 성능을 희생하지만 안전성, 표현력, 사용성을 모두 챙겨갈 수 있는 좋은 선택지이다.
추상화
서론이 길었는데 그럼 이제 본격적으로 가비지 컬렉션에 대해서 얘기해보자.
존 매커시의 원조 아이디어를 다시 가져오면: “프로그램의 어디에서도 닿지 않는 메모리는 더 이상 쓰이지 않는 것으로 간주하고, 이것들을 따로 모아뒀다가 나중에 재활용한다.” 이로부터 가비지 컬렉션을 추상적인 두 단계로 나눌 수 있다.
- 가비지 찾기 (Garbage Detection): 살아있는 객체(Live Object, Reachable Object)와 가비지 객체(Dead Object, Unreachable Object, Garbage)를 구분한다.
- 가비지 수집 (Garbage Collection): 가비지 객체의 메모리를 수집한다. 곧바로 해제할 수도 있고, 아니면 따로 모아놨다가 재활용할 수도 있다.
실제로 이 두 단계는 완전히 구분되지 않은 채로 얽혀 있을 수 있고, 특히 수집 방법은 찾는 방법에 크게 의존하게 된다.
좀더 자세하게 들어가기 전에 가비지 컬렉션 세계에서 공통적으로 나오는 몇 가지 재밌는 개념들이 있다.
루트 집합 (Root Set)
실행 중인 프로그램이 즉시 사용할 수 있는 객체들을 루트 집합이라고 한다. “즉시 사용할 수 있다”는 뜻은 어떤 포인터를 따라가지 않고도 곧바로 접근 가능하다는 뜻이다. 예를 들면, 지금 실행 중인 함수의 스택에 올라가 있는 변수, 글로벌 변수, 정적 모듈, 등이 있다.
이걸 바탕으로 앞의 두 단계 추상화를 다시 생각해보자. 그러면 “가비지 찾기” 단계는 곧 “루트 집합에서부터 시작해서 닿을 수 있는 모든 객체”를 찾는 문제가 된다3.
컬렉터와 뮤테이터
보통 가비지 컬렉션은 프로그래밍 언어에 기본적으로 장착되어 있거나 어떤 라이브러리에 핵심 컴포넌트로 구현되어 있다. 이때 가비지 컬렉션을 담당하는 에이전트를 가비지 컬렉터, 혹은 그냥 컬렉터(Collector)라고 부른다. 반면 흥미롭게도 가비지 컬렉션 연구자들은 사용자 프로그램을 “뮤테이터(Mutator)”라고 부르는데, 왜냐하면 컬렉터가 관리해야 하는 객체들의 메모리 상태를 사용자 프로그램이 계속해서 바꾸기 (mutate) 때문이다. 처음 이 이름을 들었을 때 철저하게 가비지 컬렉션 입장만 생각하고 이름 지은 것 같아서 웃겼다.
박싱 (Boxing)
가비지 찾기 단계가 완료되고 나면 가비지 수집 단계에서 컬렉터가 각각의 객체에 대해서 “얘는 가비지임” 혹은 “얘는 가비지 아님”을 알 수 있어야 한다. 이게 가능하려면 해시 테이블에 객체마다 메타데이터를 기록하던지, 아니면 객체마다 추가로 메타데이터를 덧씌워서 기록하던지, 둘 중 하나밖에 없다. 해시 테이블은 생각보다 비용이 크고 캐시 친화적이지 못하기 때문에 대부분의 가비지 컬렉션은 후자의 방법, 즉 객체마다 메타데이터를 덧씌우는 방식을 택하는데 이걸 박싱이라고 한다.
박싱은 그 이름처럼 객체를 어떤 상자(Box)에다 넣고 상자 겉면에 객체와 관련된 메타데이터를 기록하는 방법이라고 볼 수 있다. 기록할 메타데이터로는 객체의 생존여부, 객체의 지금까지의 수명, 객체의 크기, 객체가 담고 있는 값의 타입 등이 있다.
당연하지만 이로 인해 발생하는 오버헤드는 피할 수 없는 트레이드 오프이다. 먼저 헤더(박스 겉면)의 메타데이터를 봐서 메모리 레이아웃을 파악한 뒤에 필드(포인터)를 따라가서 실제 값이 담긴 객체에 접근해야 한다. 헤더와 필드는 서로 다른 메모리 구역에 위치할 수 있다. 그래서 간접적인 메모리 오버헤드 때문에 캐시 미스가 자주 발생할 수 밖에 없다.
그럼 이제 진짜 가비지 컬렉션을 얘기해보자. 방법은 크게 두 갈래로 나뉜다.
각 객체의 참조 횟수를 추적해서 0이 되면 즉시 수집하는 레퍼런스 카운팅(Reference Counting)과, 주기적으로 지금 쓰고 있는 객체와 안쓰는 가비지를 추적해서 가비지만을 수집하는 트레이싱 컬렉션(Tracing Collection)이 있다.
레퍼런스 카운팅
레퍼런스 카운팅은 두 단계 추상화를 다음과 같이 구현한다.
- 가비지 찾기: 모든 객체를 박싱해서 각 객체마다 지금 사용되고 있는 횟수를 기록한다. 프로그램이 실행되는 동안 객체를 참조하면 횟수를 증가시키고 객체 사용이 끝나면 횟수를 감소시킨다. 그러다가 참조 횟수가 0이되는 즉시 가비지로 판단한다.
- 가비지 수집: 참조 횟수가 0인 객체의 모든 메모리를 해제한다.
이 방식의 특징은 위의 1, 2가 동시에 일어난다는 점이다.
레퍼런스 카운팅은 여러가지 장점이 있다. 일단 아이디어가 간단해서 이해하기 쉽다. 그래서 메모리 관리 뿐 아니라 리소스 관리에도 쓰인다. 그리고 객체를 다 쓴 즉시 수집하기 때문에 객체의 수명이 명확한 편이라 메모리를 필요한 만큼만 사용하는 경향이 있다. 이 덕분에 객체에 대한 종료 처리도 꽤 예측한 대로 동작한다 (Finalisation). 응답성도 좋아서 실시간 시스템에 많이 채택되었다. 끝으로 아이디어가 간단한 만큼 구현도 간단하다고 하는데… CPython 구현 코드에서 레퍼런스 카운터를 늘리거나 줄이는 코드를 검색하면 엄청 많은 곳에서 발견되어서, 개인적으로 그렇게 쉬울 거라는 생각은 들지 않는다.
그런데 주변을 둘러보면, 레퍼런스 카운팅만을 가비지 컬렉션으로 채택한 언어나 프로그램은 거의 없다. 그 이유는 다음과 같은 몇 가지 근본적인 한계 때문이다.
정확성의 한계
가장 큰 한계는 바로 그 유명한 순환 참조 문제다 (Circular Reference). 어떤 두 객체가 서로를 참조해버리면 다른 모든 곳에서 이 객체에 대한 작업을 끝내더라도 이들의 참조 횟수는 항상 1(이상)이기 때문에 절대로 수집되지 않는다 (Memory Leak). 이런 경우가 얼마나 있겠냐 싶은데 실제로 꽤 많다. 예를 들면 LRU 캐시 등의 구현에 사용되는 더블 링크드 리스트나 계산 편의를 위해 부모 노드로 가는 포인터를 추가한 트리의 노드 등에서 순환 참조가 발생한다.
다시 말해 레퍼런스 카운팅은 가비지의 보수적인 근사값만을 판단한다는 근본적인 한계가 있다. 어떤 객체의 참조 횟수가 0이면 항상 가비지이지만, 그 역은 참이 아닐 수도 있다. 이로 인해 모든 가비지를 수집할 수 없게 되고 프로그램은 메모리를 누수한다.
성능 오버헤드
생각보다 오버헤드가 크다는 단점도 있다.
먼저 모든 객체의 “레퍼런스”를 추적해야 하는데, 말 그대로 모든 객체, 즉 언어가 제공하는 원시 데이터 타입과 사용자가 정의하는 타입까지 전부 다 추적해야 한다. 이로 인해서 객체의 메모리를 미세하게 표현하고 조절하는데 제약이 생긴다. 예를 들어, 항상 메모리에 상주하는 정적 객체도 사용할 때마다 레퍼런스를 늘리거나 줄여야 한다. 또는, 금방 사용되고 버려질 생명주기를 정확하게 알고 있는 객체도 사용할 때마다 참조 횟수를 업데이트 해야 한다. 그래서 많은 가비지 컬렉션에서는 이런 경우를 위해 미세 조정을 할 수 있는 도구를 제공하기도 한다.
또, 참조 “횟수”를 세기 위해서는 헤더에 정수 값을 담아야 한다. 그런데 프로그램이 실행되면서 최대 몇 번의 참조가 이뤄질지를 미리 아는 것은 불가능하기 때문에, 적당한 크기의 정수를 선택하는 것도 어려운 문제다. 너무 큰 정수를 선택하면 오버헤드가 있고, 그렇다고 너무 작은 정수를 선택하면 정확한 참조 횟수를 담지 못할 수 있다4.
게다가 어떤 커다란 객체의 카운트가 0이 되었을 때 거기 연결된 수많은 자식 객체들이 모두 다 해제되어야 하는 상황에서는 일관되고 예측 가능한 성능이 깨진다는 점도 무시할 수 없다. 이를 피하기 위해서 레퍼런스 카운팅의 최적화 연구에서는 연산을 미루는 것들이 많다 (Deferred Reference Counting).
결정적으로 프로그램의 작업량에 비례해서 메모리 관리 오버헤드가 늘어난다. 예를 들어 a = b + 1 이라는 코드를 실행한다고 하자. 그러면 a는 값이 쓰여지기 때문에 참조 횟수를 증가시키고, b는 값을 읽기 때문에 참조 횟수를 줄인다. 참조 횟수가 줄어드는 경우에는 이 값이 0이 되는지도 확인해야 한다. 두 변수를 사용하는 단순한 한 줄의 코드를 실행하는데 두 객체를 모두 업데이트 해야 한다. 사용하는 변수가 늘어날수록 오버헤드도 비례해서 증가한다. 즉, 프로그램의 작업량이 많아지면 오버헤드도 같이 증가할 수 밖에 없다.
모든 작업이 암묵적인 쓰기 연산
개인적으로 겪었던 단점 중 하나는 바로 객체를 읽는 모든 연산이 암묵적으로 쓰기 연산이 되어버린다는 것이었다. 이로 인해서 데이터를 단순히 읽기만 하는 것이 원천적으로 불가능하다. 예를 들어 커다란 데이터 덩어리를 여러 프로세스 사이에 읽기만 하는 목적으로 공유하는 경우, 커널이 제공하는 최적화 중 하나인 쓰기 시 복사(Copy-on-Write)를 적용하는 것이 불가능해져서 예상했던 것보다 엄청나게 많은 메모리를 잡아먹게 된다. 그래서 병렬 처리에 애를 먹었던 적이 있다. 이럴 때는 다른 라이브러리를 이용해서 읽기만 할 데이터를 공유 메모리에 올리거나 하는 방식으로 우회해야 한다.
모든 연산이 참조 횟수에 쓰기 작업을 해야 하기 때문에, 멀티 쓰레드 환경에서는 필연적으로 경쟁 상태가 발생한다 (Race Condition). 그래서 공유 메모리 병렬 처리 (Shared Memory Parallelism), 다시 말해 멀티 쓰레드 환경에서의 런타임 구현을 더 복잡하게 만든다. 많은 언어에서는 그래서 구현을 간단하게 하기 위해 GIL(Global Interpreter Lock)을 적용했다.
레퍼런스 카운팅의 현재
이러한 한계들로 인해서 현대에는 레퍼런스 카운팅만을 도입한 언어는 잘 없다. 보통은 다음 둘 중 하나를 택한다.5
- 하이브리드 접근: 레퍼런스 카운팅을 기본으로 하되, 순환 참조를 피하기 위해서 보조로 트레이싱 컬렉션을 같이 장착한다. 예를 들면 파이썬과 스위프트가 있다.
- 제약된 레퍼런스 카운팅: 순환 참조를 방지하도록 소유권 규칙을 강제한다. Rust의
Rc<T>가 있다.
그리고 레퍼런스 카운팅은 생각보다 최적화할 여지가 많지 않은 것 같다. 왜냐하면 가비지 컬렉션과 관련된 연구는 주로 아래에 설명할 트레이싱 컬렉션을 기반으로 하는 것이 많기 때문이다.
트레이싱 컬렉션
트레이싱 컬렉션은 이름 그대로 가비지를 “추적해서” 수집한다. 구체적으로는 가비지 컬렉션 추상화의 두 단계, 가비지를 찾는 단계와 가비지를 수집하는 단계를 정직하게 나누어 구현한다.
트레이싱 컬렉션은 다양한 알고리즘들이 연구되어 왔다. 이들의 공통된 특징 중 하나는 가비지를 찾고 수집하는 방식뿐만 아니라 수집한 가비지 메모리를 곧바로 해제하지 않고 이후의 할당에 재활용하는데에도 초점이 맞춰져 있다는 것이다. 메모리 할당과 수집한 메모리를 재사용하는 것은 동전의 양면과도 같아서 트레이싱 컬렉터는 “가비지 메모리를 관리하기 위한 시스템”이라고 생각할 수도 있다.
마크 스윕 컬렉션 (Mark & Sweep Collection)
마크 스윕 컬렉션은 이름 그대로 마킹 단계와 스위핑 단계를 나누어 구현한 알고리즘으로 존 매커시가 Lisp에 구현했던 원조 가비지 컬렉션 알고리즘이다.
- 가비지 찾기: 마킹 단계. 루트 집합으로부터 시작해서 닿을 수 있는 모든 객체를 추적해서 “살아있는 객체”로 구분한다.
- 가비지 수집: 스위핑 단계. “살아있는 객체”가 아닌 모든 객체들은 죽은 객체, 즉 가비지로 판단할 수 있다. 가비지 객체들은 곧바로 해제하지 않고 수집해서 이후 할당에 재활용한다.
여기까지는 되게 추상적인, 잘 알려진 설명이다. 여기서 좀더 구체적으로 파고 들면 다양한 재미난 것들이 튀어 나온다.
프리 리스트 (Free List)
가비지 메모리를 따로 수집해서 모아놨다가 이후 할당에 다시 재활용하는 것은 합리적으로 보인다. 그런데 이걸 어떻게 구현할까?
원조 Lisp에서 도입된 방법은 바로 프리 리스트이다. 그리고 이건 생각보다 많은 곳에서 여전히 쓰이고 있다.
프리 리스트는 수집된 가비지 메모리 덩어리를 링크드 리스트의 형태로 관리하는 방식이다. 각각의 메모리 덩어리는 다음 메모리 덩어리를 가리키는 포인터를 담고 있다. 뮤테이터로부터 새로운 메모리 할당이 요청되면 프리 리스트를 훑으면서 적절한 크기의 메모리 덩어리를 찾아서 할당에 사용한다. 그리고 수집되는 메모리 덩어리들은 프리 리스트에 추가된다.
설명을 보면 알겠지만 프리 리스트는 이해하기 쉬워서 구현이 쉬운 편이지만 몇 가지 문제가 있다. 먼저 프로그램의 워크로드에 맞는 “적절한” 크기의 블록을 찾는 정책에 따라서 성능이 달라질 수 있다. 모든 메모리 할당이 링크드 리스트 탐색을 필요로 하기 때문에 이 정책은 결국 어떤 식으로 리스트를 살펴볼 것인지에 대한 것이다. 예를 들어 가장 이해가 쉬운 Next-Fit 할당은 링크드 리스트를 탐색하는 포인터를 유지하면서 그 포인터를 이용해서 리스트를 순서대로 훑다가 처음으로 만난 적당한 크기(메모리 할당 요청을 수행할 수 있는 최소의 크기)의 덩어리를 만나면 돌려준다. 리스트의 끝까지 간 경우 다시 리스트의 시작으로 돌아와서 처음부터 시작한다. 리스트가 비었거나 다 살펴봤는데도 적당한 크기가 없으면 새로 할당하는 식이다. 이 외에도 가장 작은 크기부터 탐색해서 처음으로 할당 요청 크기 이상을 만날 경우 돌려주는 First-Fit과, 가장 적절한 크기의 메모리 덩어리를 찾아서 파편화를 줄이기 위한 Best-Fit 방식 등이 있다.
하지만 이렇게 할당 정책을 잘 구현하고 선택하더라도 메모리 단편화를 근본적으로 해결하지는 못한다. 게다가 프로그램이 실행되면서 프리 리스트가 계속 자라기만 한다면 탐색 시간이 증가할 수도 있어서 프리 리스트 자체도 관리해야 하는 비용이 된다.
실제 구현에서는 이걸 조금이라도 해결하기 위해서 마치 메모리 풀처럼 여러 개의 적당한 크기의 블럭으로 구성된 프리 리스트를 유지하는, Segregated Free List 방식을 많이 사용한다. 예를 들면 8바이트, 16바이트, 32바이트, …. 등 특정 크기들에 대해서 각각 프리 리스트를 만들어서 관리하는 방식이다.
삼색 조합 (Tri-Colour Scheme)
마크-스윕 컬렉션(과 그 변형)은 저마다의 방식으로 객체의 상태를 구분하는데, 가장 널리 쓰이는 방법 중 하나는 아래의 세 가지 색깔을 이용하는 방식이다.
- 흰색 (Unmarked)
- 마킹 단계 시작 전: 모든 노드의 초기 상태를 나타낸다. 컬렉터는 루트 집합으로부터 닿을 수 있는 흰색 노드를 하나씩 칠해 나아간다.
- 마킹 단계 완료 시: 가비지.
- 스위핑 단계에서: 수집 대상이다. 얘네들을 프리 리스트에 모아놨다가 나중에 재사용한다.
- 회색 (In-Marking): 마킹 단계에서만 임시로 쓰인다. 어떤 객체가 루트 집합으로부터 닿긴 했는데 아직 그 자식들(포인터를 따라갈 수 있는 객체들)까지는 살펴보지 않은 상태를 뜻한다.
- 검은색 (Marked): 루트 집합으로부터 닿을 수 있는 객체들 (Reachable Objects), 즉 “살아있는 객체들 (Live Object)”을 뜻한다. 얘네들은 아직 프로그램이 사용하고 있는 객체일 수 있기 때문에 스위핑 단계에서 살려둔다. 스위핑이 끝나고 나면 다시 색깔을 뒤집어서 흰색(초기 상태)으로 돌려둔다.
이걸 바탕으로 트레이싱 컬렉션은 어떤 실행 시점에서 메모리 상의 객체들로 이뤄진 그래프를 탐색하면서 색깔을 칠하는 문제로 생각해볼 수 있다. 나의 이해를 위해 이번에는 엑스칼리-드로우로 그림을 한번 그려봤다. 각 그림의 설명은 그림 밑에 적었다.
 제일 처음에는 모든 노드(객체)들이 흰색이다. 객체를 따라 다른 객체에 접근할 수 있다면 엣지가 있다 (Reachable).
제일 처음에는 모든 노드(객체)들이 흰색이다. 객체를 따라 다른 객체에 접근할 수 있다면 엣지가 있다 (Reachable).
 마킹 단계는 루트 집합에서 시작한다. 가장 먼저 노드를 하나씩 방문하면서 회색으로 칠한다.
마킹 단계는 루트 집합에서 시작한다. 가장 먼저 노드를 하나씩 방문하면서 회색으로 칠한다.
 자식 노드로 넘어갈 때 부모 노드는 검은색으로 칠하고 자식 노드는 회색이 칠한다.
자식 노드로 넘어갈 때 부모 노드는 검은색으로 칠하고 자식 노드는 회색이 칠한다.
 이렇게 흰색 → 회색 → 검은색의 물결이 진행되는데, 모든 닿을 수 있는 노드는 회색을 기준으로 한쪽은 흰색 다른 한쪽은 검은색인 모습이 된다.
이렇게 흰색 → 회색 → 검은색의 물결이 진행되는데, 모든 닿을 수 있는 노드는 회색을 기준으로 한쪽은 흰색 다른 한쪽은 검은색인 모습이 된다.
 마킹 단계의 모든 탐색이 끝나고 나면 검은색 노드는 살아있는 객체이다. 그리고 흰색 노드들은 안전하게 가비지로 판단할 수 있다.
마킹 단계의 모든 탐색이 끝나고 나면 검은색 노드는 살아있는 객체이다. 그리고 흰색 노드들은 안전하게 가비지로 판단할 수 있다.
 스위핑 단계에서는 컬렉터가 관리 대상 메모리 구역을 전부 훑으면서 흰색 노드를 수집한다. 이 노드들은 나중에 재활용 하기 위해서 프리 리스트에다 추가한다.
스위핑 단계에서는 컬렉터가 관리 대상 메모리 구역을 전부 훑으면서 흰색 노드를 수집한다. 이 노드들은 나중에 재활용 하기 위해서 프리 리스트에다 추가한다.
 스위핑 단계에서 가비지 노드들을 다 프리 스토리지 리스트에 넣고 나면, 이번 컬렉션을 살아남은 검은 노드들이 다음 컬렉션에서 관리될 수 있도록 다시 흰색으로 칠한다.
스위핑 단계에서 가비지 노드들을 다 프리 스토리지 리스트에 넣고 나면, 이번 컬렉션을 살아남은 검은 노드들이 다음 컬렉션에서 관리될 수 있도록 다시 흰색으로 칠한다.
실제 구현은 다양한 요구사항을 만족해야 해서 디테일이 좀 다를 순 있지만 큰 그림에서는 이게 핵심이다. 참고로 원조 구현에서는 그래프 색칠에 사용되는 그래프 탐색을 DFS로 구현하였다.
세상을 멈추는 조정 (Stop-The-World Coordination)
그런데 색을 칠하는 작업은 컬렉터가 노드의 포인터를 따라가는, 즉 포인터를 “읽는” 작업이다. 문제는 뮤테이터가 노드의 포인터에 값을 “쓸(write)” 수 있다는 것이다. 그래서 컬렉터와 뮤테이터가 동시에 실행하게 되면 컬렉터는 일관되지 못한 그래프를 읽을 수 있다.
이로 인한 가장 치명적인 이슈는 바로 마킹을 빼먹는 실수 (Missing Mark)이다. 마킹 단계에서 타이밍이 안맞으면 실제로 살아있는 객체가 검은색으로 칠해지지 않을 수 있는데, 이러면 살아있는 객체가 잘못 수집될 수 있다! 이건 아래 그림을 보면 바로 이해할 수 있다.
 먼저 메모리에 A → B → C 의 노드가 있다고 하자.
먼저 메모리에 A → B → C 의 노드가 있다고 하자.

컬렉터가 A를 검은색으로 칠하고 이제 B를 방문해서 회색으로 칠했다.
 근데 갑자기 뮤테이터가 나타나서 A와 C를 연결하고 B와 C 사이 연결을 끊어버리면 어떻게 될까?
근데 갑자기 뮤테이터가 나타나서 A와 C를 연결하고 B와 C 사이 연결을 끊어버리면 어떻게 될까?
 컬렉터는 B에 매달린 자식 노드가 없기 때문에 B를 검은색으로 칠하고 다음 노드를 찾아 떠나가버린다. 그런데 A → C에 새로운 링크가 연결 되었음에도 불구하고, A를 이미 검은색으로 칠했기 때문에 C는 절대로 칠해지지 않는다.
컬렉터는 B에 매달린 자식 노드가 없기 때문에 B를 검은색으로 칠하고 다음 노드를 찾아 떠나가버린다. 그런데 A → C에 새로운 링크가 연결 되었음에도 불구하고, A를 이미 검은색으로 칠했기 때문에 C는 절대로 칠해지지 않는다.
 그래서 C는 닿을 수 있는 살아있는 객체인데도 불구하고 흰색으로 남겨져 있다가, 곧이은 스위핑 단계에서 수집되어 버린다. 이렇게 되면 A가 가리키는 C의 메모리는 더 이상 유효하지 않게 되고, 이후 뮤테이터가 여기 접근하면 정의 되지 않은 행동에 의해 프로그램이 죽어버린다.
그래서 C는 닿을 수 있는 살아있는 객체인데도 불구하고 흰색으로 남겨져 있다가, 곧이은 스위핑 단계에서 수집되어 버린다. 이렇게 되면 A가 가리키는 C의 메모리는 더 이상 유효하지 않게 되고, 이후 뮤테이터가 여기 접근하면 정의 되지 않은 행동에 의해 프로그램이 죽어버린다.

뮤테이터와 컬렉터가 동시에 동작하는 경우에는 마킹 단계의 정확성이 깨져버린다. 그래서 이를 막기 위해서 마크 스윕 컬렉션은 그 악명 높은 STW(Stop-The-World) 조정을 도입한다. 컬렉터가 모든 노드에 대한 마킹 작업을 완료할 때까지 프로그램(뮤테이터)을 완전히 멈춰서 색깔이 잘못 칠해지는 것을 막는다.
점진적 컬렉션 (Incremental Collection)
올바른 가비지 컬렉션을 위해서 STW가 필요하다는 것은 자명하다. 하지만 마크 스윕 컬렉션이 처음 Lisp에 도입됐던 그 당시에는 프로그램이 수 밀리초에서 수 초간 멈춰버리는 것이 비일비재했는데, 이로 인해서 사용자 경험이 좋지 못했다. 그래서 초기의 마크 스윕 컬렉션은 이 나쁜 응답성 때문에 실시간 어플리케이션에 적합하지 못하다는 의견이 많았다.
이걸 해결하기 위한 것이 바로 점진적 컬렉션이다. 마킹을 할 때 뮤테이터를 멈춘 다음 처음부터 끝까지 한번에 진행하는게 아니라, 마킹 작업을 조금씩 잘라서 (Slicing) 수행한 뒤에 뮤테이터한테 턴을 넘기고, 이후 뮤테이터가 일정 시간 후에 다시 컬렉터한테 턴을 넘기는 방식으로 서로 턴을 주고받으면서 너무 긴 정지 시간(Pause Time)을 겪지 않도록 반응성을 챙기는 것이다. 구체적으로는 최대 정지 시간을 “예측할 수 있는” 수준으로 제한해서 가비지 컬렉터와 뮤테이터 사이를 조율할 수 있게 만들어 마크 스윕 컬렉션을 실시간 어플리케이션에 사용할 수 있을 정도의 반응성을 획득하게 만들었다.
쓰기 배리어
하지만 점진적 컬렉션은 STW를 도입하게 했던 문제점, 즉 Missing Mark 문제점을 다시 만난다. 이걸 어떡하면 좋을까?
Missing Mark 문제점을 조금 다르게 “검은색 객체가 흰색 객체를 가리키면 안된다”라는 불변식으로 표현할 수 있다. 앞의 예시에서도, 컬렉터가 A → B → C의 체인을 방문하면서 차례로 A를 검은색으로 칠하고 B를 회색으로 칠하는 도중, 뮤테이터가 갑자기 끼어들어서 이미 칠해진 검은색 노드 A가 아직 칠해지지 않은 하얀색 노드 C를 가리키면서 이 불변식이 깨져버렸기 때문에 발생한 것이다.
이 불변식이 깨지는 걸 막기 위해서 “배리어”를 도입한다. 어떤 포인터 연산이 발생할 때 이것들을 추적해서 불변식이 깨지지 않게 하면 된다. 이때 쓰기 연산에 배리어를 도입하면 쓰기 배리어 (Write Barrier), 읽기 연산에 도입하면 읽기 배리어 (Read Barrier)라고 하고 보통은 쓰기 배리어를 더 많이 쓰는 듯 하다.
쓰기 배리어의 역할은 좀 헷갈릴 수도 있다. 왜냐하면 같은 “쓰기 배리어”라는 컨셉이 점진적 컬렉션에도 있고 아래에서 설명할 세대 별 가비지 컬렉션에서도 존재하기 때문이다. 일단 여기서는 점진적 컬렉션을 중심으로 살펴보자.
구체적으로는 두 가지 전략이 있다.
- 다익스트라(Dijkstra)의 쓰기 배리어: 검은색 노드가 흰색 노드를 가리키려고 할 때, 이 흰색 노드를 회색으로 칠해서 불변식을 유지한다.
- 스틸(Steele)의 쓰기 배리어: 검은색 노드를 수정할 때, 이걸 잠깐 회색으로 돌린다. 이렇게 하면 검은색 → 흰색이 아니라 회색 → 흰색이 되므로 불변식이 유지된다.
쓰기 배리어는 모든 포인터 쓰기 연산에서 추가적으로 메모리를 관리하기 위한 로직을 실행하는 메커니즘이다. 모든 포인터 연산을 추적하고 자동으로 이 메커니즘을 삽입하려면 가비지 컬렉션만으로는 부족하고 컴파일러의 도움을 받아야 한다. 그래서 쓰기 배리어까지 적용된 완전한 트레이싱 컬렉션은 라이브러리나 패키지가 아니라 프로그래밍 언어 수준에서 구현될 수 밖에 없다.
시작점 스냅샷 (Snapshot-At-The-Beginning Invariant)
점진적 컬렉션의 또 다른 문제점은 컬렉터가 멈춰있는 동안 뮤테이터가 새로운 객체를 계속 할당할 수 있다는 점이다. 그래서 이론적으로는 마킹 단계가 끝나지 않을 수 있다. 컬렉터가 열심히 그래프를 색칠해 나가다가 잠깐 멈추고 뮤테이터한테 턴을 넘겨줬을 때, 뮤테이터가 그래프에 새로운 닿을 수 있는 살아있는 객체들을 추가한 다음 다시 턴을 컬렉터에게 넘겨주고, … 를 끊임없이 진행한다면 충분히 가능하다.
그래서 이 문제를 해결하기 위해서 추가적으로 도입한 불변식이 바로 시작점 스냅샷 불변식 (Snapshot-At-The-Beginning Invariant, or SATB)이다. 마킹 단계를 시작하는 순간 전체 그래프의 스냅샷을 찍어서 여기에 찍힌 노드들만 마킹한다. 이렇게 하면 반드시 마킹 작업이 끝난다는 것이 보장되어서 효율적인 컬렉션이 가능하다.
근데 이거 실제로 구현은 어떻게 해야할까? 진짜로 마킹 시작할 때 뮤테이터를 멈춘 다음에 힙 메모리 전체의 상태를 스냅샷으로 찍듯이 어딘가에 저장하는 구현은 대단히 비효율적일 것이다. 실제 많은 프로그래밍 언어에서는 아래의 두 가지 기발한 핵심 메커니즘으로 SATB를 구현한다.
가장 먼저 쓰기 배리어의 불변식을 조금 느슨하게 한 “유아사(Yuasa)의 삭제 배리어”를 적용한다. 마킹의 올바름을 위해서 도입한 “검은 노드는 흰 노드를 가리키면 안된다”를 “강한 삼색 불변식(Strong Tri-Colour Invariant)”이라고 하자. 유아사의 핵심 아이디어는 이걸 조금 느슨하게 한 “약한 삼색 불변식(Weak Tri-Colour Invariant)”를 도입하는 것인데, 바로 “검은 노드가 가리키는 흰 노드는 반드시 다른 회색 노드로부터 닿을 수 있는 경로에 있어야 한다”는 것이다.
기존의 쓰기 배리어 대신 삭제 배리어를 도입하면 어떻게 되는지 살펴보자. 삭제 배리어는 그 이름대로 어떤 포인터 간의 연결이 끊어질 때, 끊긴 애(삭제되는 애)를 살려두는 것이 핵심이다. 즉, 쓰기 연산이 일어날 때 덮어써지는 값을 회색으로 칠해서 보호한다. 앞의 예시를 다시 가져와서 그림으로 보자.
A → B → C의 체인이 있다가 컬렉터가 A를 마킹하고 B를 회색으로 칠한 상황이다. 이 상태로 컬렉터가 뮤테이터한테 턴을 넘긴다.
 먼저 뮤테이터가 A와 C를 연결한다고 하자. 이 연산은 곧 A가 가리키던 필드를 C로 덮어 쓴 것이다. 삭제 배리어는 A가 가리키던 기존 값인 B를 보호하기 위해서 B를 회색으로 칠한다(사실 이미 칠해져있음). 이렇게 하면 유아사의 약한 삼색 불변식을 만족한다.
먼저 뮤테이터가 A와 C를 연결한다고 하자. 이 연산은 곧 A가 가리키던 필드를 C로 덮어 쓴 것이다. 삭제 배리어는 A가 가리키던 기존 값인 B를 보호하기 위해서 B를 회색으로 칠한다(사실 이미 칠해져있음). 이렇게 하면 유아사의 약한 삼색 불변식을 만족한다.
 그 다음 뮤테이터가 B와 C 사이를 끊는다고 하자. 이 연산은 곧 B가 가리키던 필드를 Null 값으로 덮어 쓴 것이다. 따라서 삭제 배리어는 역시 B가 가리키던 기존 값인 C를 보호하기 위해서 C를 회색으로 칠한다. 역시 약한 삼색 불변식을 만족한다.
그 다음 뮤테이터가 B와 C 사이를 끊는다고 하자. 이 연산은 곧 B가 가리키던 필드를 Null 값으로 덮어 쓴 것이다. 따라서 삭제 배리어는 역시 B가 가리키던 기존 값인 C를 보호하기 위해서 C를 회색으로 칠한다. 역시 약한 삼색 불변식을 만족한다.
 컬렉터는 보수적으로 처음 마킹을 시작했을 때의 스냅샷인 A, B, C를 모두 수집하지 않고 지켜낼 수 있다.
컬렉터는 보수적으로 처음 마킹을 시작했을 때의 스냅샷인 A, B, C를 모두 수집하지 않고 지켜낼 수 있다.
여기에 추가적으로 한 가지의 메커니즘이 더 필요하다: 마킹 단계에서 할당하는 모든 객체는 미리 검은색으로 마킹하고 할당한다. 이렇게 하면 이후 스위핑 단계에서 컬렉터가 마킹 중에 할당한 모든 객체를 이미 마킹했다고 여겨, 마치 마킹 초기에 스냅샷을 찍은 것과 같은 효과를 볼 수 있다.
많은 프로그래밍 언어에서는 점진적 컬렉션과 SATB을 동시에 구현하기 위해서 유아사의 삭제 배리어를 도입하는 경우가 많다. 예를 들면 OCaml과 Go, 그리고 Java의 G1 GC가 모두 이 방식을 구현하고 있다.
이 외에도 전통적인 마크 스윕 컬렉션에는 주요한 몇 가지 한계가 있다.
가장 먼저 메모리 단편화가 있다6. 앞의 예시에서는 추상적인 그래프로 표현했지만, 그래프의 노드는 실제로는 힙의 어떤 구간에 할당된 메모리 덩어리다. 프로그램의 수명이 길어질수록 힙 구간 안에서 살아있는 객체와 가비지 객체가 뒤섞이게 되는데, 이로 인해 큰 크기의 메모리를 할당하기 어려워질 수 있다. Segregated 프리 리스트 같은 걸 도입해 이걸 완화할 순 있지만 그래도 완벽하진 않다. 결국 컬렉터가 일을 더 많이 해서 메모리를 최대한 필요한 만큼만 타이트하게 관리할지, 아니면 그냥 적당히 메모리를 낭비하고 파편화를 감수하더라도 컬렉터가 일을 덜 할지, 이 트레이드 오프 사이에서 고민하는 수 밖에 없다. 프로그램이 어떤 워크로드를 갖느냐에 따라서 튜닝해야 한다.
또 다른 본질적인 한계로는 컬렉터가 스위핑 단계에서 관리 중인 메모리 구역 전체를 살펴봐야 한다는 것이다. “마킹”이 살아있는 루트 집합으로부터 “살아있는 객체”를 따라가는 작업인 반면, “스위핑”은 반대로 전체 메모리 중에서 마킹이 안된 애를 찾아야 하기 때문에 어쩔 수 없는 한계다. 하지만 이 작업은 하드웨어의 눈부신 발전으로 생각보다는 빠르다고 한다.
마지막으로 전반적으로 마크 스윕 컬렉션에서 적용되는 컬렉터와 뮤테이터의 작업들이 캐시 친화적이지 않다는 한계가 있다. 오래 사용되는 객체들은 한번 할당되고 나면 보통 거기 계속 남아있기 마련이다. 이들 사이에 있던 가비지가 수집되어 이후 할당에 쓰이게 되면 서로 용도와 수명주기가 다른 객체들이 연속된 메모리 구간 안에 섞이게 된다. 그러면 객체에 접근하는 메모리 작업의 지역성이 나빠져서 캐시 친화적이지 못하게 되어 성능의 손해를 본다. 게다가 컬렉션이 진행될수록 살아있는 객체들의 메모리 분포가 나빠질 수 있는데, 마킹 단계에서 살펴봐야 하는 노드(객체)들이 서로 너무 먼 곳에 떨어져 있게 되면 닿을 수 있는 객체를 살펴보기 위한 그래프 탐색 역시 캐시 친화적이지 않아서 마킹 작업이 느려질 수 있다.
물론 이것들은 다양한 최적화 기법을 통해서 일정 부분은 풀 수 있다.
마크 컴팩트 컬렉션 (Mark-Compact Collection)
마크 스윕 컬렉션의 단편화 문제를 해결하기 위해서 압축(Compact) 단계를 도입한 방법이다. 마킹이 완료되고 나면 관리 중인 힙 메모리 전체를 압축하여 살아있는 객체만 인접하도록 한 쪽으로 옮기고 (Sliding) 가비지들은 다 치워버린다. 이렇게하면 메모리 덩어리 사이에 있던 구멍을 살아있는 객체로 메우게 되어 단편화를 피할 수 있다.
장점으로는 압축 과정 덕분에 다양한 크기의 객체를 할당할 수 있게 된다. 그리고 살아있는 객체들이 지속적으로 연속된 공간에 접하기 때문에 지역성이 좋아져서 메모리 접근 연산도 빨라질 수 있다.
하지만 압축 단계가 끝나면 살아있는 객체의 주소가 바뀔 수 있기 때문에, 이들을 참조하고 있던 모든 객체들의 주소 값을 압축 이후의 값으로 업데이트 해줘야 한다. 그래서 객체들을 여러 번 전부 스캔해야 할 필요가 있고, 만약 살아있는 객체의 비율이 크다면 이는 상당한 오버헤드가 된다. 그리고 객체를 옮기는 슬라이딩 과정 자체도 비용이 상당하다.
그래서 요즘은 많은 언어들이 마크 스윕 컬렉션과 마크 컴팩션 컬렉션을 합친 마크 & 스윕 & 컴팩션 컬렉션을 적용한다. 계속 스위핑을 하다가 메모리에 대한 일정 임계점을 넘기는 순간 압축을 수행하여 메모리를 효율적으로 관리하도록 한다.
복사 컬렉션 (Copying Collection)
마크 스윕 (+ 컴팩트) 컬렉션처럼 추적하는 방식 외에도 트레이싱 컬렉션으로 분류되는 방식이 바로 복사 컬렉션이다.
기본적으로 메모리 공간을 넉넉하게 할당한 다음 이걸 반으로 쪼갠다. 그러고 할당은 한쪽 공간에서만 한다. 계속 할당하다가 이게 꽉차면 전체(할당에 쓰인 절반)를 훑으면서 가비지는 스킵하고 살아있는 객체만 반대쪽 공간으로 옮긴다. 이게 기본이다. 구체적으로는 두 개의 비슷하면서도 조금 다른 알고리즘이 있다.
체이니의 방법 (Cheney’s Copying Collection)
1970년에 개발된 복사 컬렉션 방식이다. STW와 비슷하게 Stop & Copy 방식의 복사 컬렉션이다.
이 시대의 하드웨어 스펙의 한계로 인해 당시 Lisp에 구현된 나이브한 마크 스윕 알고리즘은 그래프를 DFS로 탐색하다가 스택 오버플로우가 날 위험이 있었다. 이를 해결하기 위해 체이니는, 1969년에 연구되었던 초기의 복사 컬렉션(Fenichel & Yochelson)을 확장하여, BFS 기반의 가비지 탐지와 함께 메모리 단편화를 없애는 비재귀적인 구현을 소개했다.
먼저 힙을 두 개의 세미 공간, fromspace와 tospace로 나눈다.
- fromspace: 모든 할당이 처음 일어나는 공간. 연속된 큰 메모리 구역에 커서를 기록해두고 이걸 증가시키면서 메모리를 할당한다. fromspace가 꽉차면 프로그램을 멈추고 가비지 컬렉션을 시작한다.
- tospace: 가비지 컬렉션이 시작되면 fromspace 구역에 살아있는 객체를 찾아서 tospace로 복사한다.
이후에 모든 살아있는 객체가 tospace로 이동하고 나면, fromspace와 tospace를 개념적으로 바꾸고 (Flip) 멈췄던 뮤테이터를 다시 풀어준다. 그리고 이후 할당은 fromspace(예전 tospace)에서 일어난다.
이게 왜 트레이싱이냐고 할 수도 있는데 동작을 자세히 살펴보면 트레이싱 맞다. 역시 그림으로 보자.
 복사 컬렉션에서는 fromspace에서만 할당이 일어난다. 루트 집합은 fromspace에 할당된 루트 객체를 가리키는 포인터다. fromspace가 꽉차면 가비지 컬렉션이 시작된다. (그림에서 빼먹었는데 왼쪽 절반이 fromspace이고 오른쪽 절반이 tospace임)
복사 컬렉션에서는 fromspace에서만 할당이 일어난다. 루트 집합은 fromspace에 할당된 루트 객체를 가리키는 포인터다. fromspace가 꽉차면 가비지 컬렉션이 시작된다. (그림에서 빼먹었는데 왼쪽 절반이 fromspace이고 오른쪽 절반이 tospace임)
 먼저 루트 객체를 tospace에 복사하고 scan과 free 포인터를 유지한다. scan은 아직 스캔하지 않은 첫번째 객체를 가리키고, free는 다음에 복사할 위치를 가리킨다.
먼저 루트 객체를 tospace에 복사하고 scan과 free 포인터를 유지한다. scan은 아직 스캔하지 않은 첫번째 객체를 가리키고, free는 다음에 복사할 위치를 가리킨다.
 [scan, free) 구간의 객체들이 곧 “이번 컬렉션을 살아남아서 복사 완료했지만 아직 자식까지는 스캔하지 않은 객체들”이 된다. 따라서, scan부터 시작해서 한 객체 씩 (즉, 큐에서 꺼내서) 닿을 수 있는 객체를 살펴보고, 얘가 fromspace에 있으면 tospace의 free 이후에 넣으면서 free를 증가한다. 이러면 자연스럽게 tospace에 복사하는 것 자체가 큐를 이용한 BFS가 된다.
[scan, free) 구간의 객체들이 곧 “이번 컬렉션을 살아남아서 복사 완료했지만 아직 자식까지는 스캔하지 않은 객체들”이 된다. 따라서, scan부터 시작해서 한 객체 씩 (즉, 큐에서 꺼내서) 닿을 수 있는 객체를 살펴보고, 얘가 fromspace에 있으면 tospace의 free 이후에 넣으면서 free를 증가한다. 이러면 자연스럽게 tospace에 복사하는 것 자체가 큐를 이용한 BFS가 된다.
 이렇게 하나 씩,
이렇게 하나 씩,
 하나 씩,
하나 씩,
 하나 씩 BFS를 수행하다 보면,
하나 씩 BFS를 수행하다 보면,
 결국 scan이 free를 만나게 되는데, 이러면 큐를 다 쓴 것이다.
결국 scan이 free를 만나게 되는데, 이러면 큐를 다 쓴 것이다.
 복사가 완료되고 나면 두 세미 공간을 Flip해서 fromspace와 tospace의 역할을 바꾸고 루트 집합이 가리키던 포인터를 새로 업데이트한다. 명시적인 큐를 도입하지 않았을 뿐이지 tospace 자체를 암묵적인 큐로 활용해서 살아있는 객체들을 BFS로 스캔한 것과 동일하다. (이해를 돕기 위해서 그림에 삼색 조합을 적용했지만, 실제 체이니의 구현에서는 색깔이 있진 않았다.)
복사가 완료되고 나면 두 세미 공간을 Flip해서 fromspace와 tospace의 역할을 바꾸고 루트 집합이 가리키던 포인터를 새로 업데이트한다. 명시적인 큐를 도입하지 않았을 뿐이지 tospace 자체를 암묵적인 큐로 활용해서 살아있는 객체들을 BFS로 스캔한 것과 동일하다. (이해를 돕기 위해서 그림에 삼색 조합을 적용했지만, 실제 체이니의 구현에서는 색깔이 있진 않았다.)
간단해 보이는 이 알고리즘은 생각보다 빠르다. 일단 연속적인 큰 메모리 구간을 가져다 쓰는 거라서 지역성이 좋아 캐시 친화적이다. 게다가 메모리 할당이 그냥 포인터 주소를 증가시킨 다음에 돌려주는 덧셈 연산에 불과해서 굉장히 빠르다 (Bump Pointer Allocation). 하지만 전체 공간을 좀 넉넉하게 할당해두고 절반은 컬렉션을 위해서 남겨놔야 하기 때문에 메모리 오버헤드가 크다 (최소 100%).
베이커의 방법 (Baker’s Incremental Copying Collection)
1978년에 구현된 최초의 실시간 컬렉션이다. 체이니의 복사 컬렉션을 점진적으로 할 수 있게 확장했다. 체이니의 방식과 마찬가지로 fromspace와 tospace로 나뉘어져있지만, 핵심은 다음 세 가지 불변식을 지켜서 컬렉터와 뮤테이터가 동시에 실행할 수 있게끔 하는 것이다.
- 뮤테이터는 절대 흰색 객체를 볼 수 없다.
- 모든 새 객체는 회색으로 할당된다.
- 읽기 배리어를 통해 흰색 객체의 접근을 막는다.
체이니와의 미묘한 차이점 중 하나는 새 객체는 tospace에 회색으로 할당된다는 것이다. 동시에 컬렉터는 fromspace에서 살아있는 객체를 점진적으로 tospace로 복사한다. 그러면 fromspace는 점차 줄어들고, tospace에는 새로 할당된 객체(회색)와 fromspace에서 살아남아 복사된 객체로 채워진다.
베이커 방법의 특징은 읽기 배리어(Read Barrier)를 사용한다는 것이다. 뮤테이터가 포인터를 역참조할 때마다 그 객체가 fromspace에 있는지 확인한다. 만약 fromspace에 있다면 즉시 tospace로 복사하고 포인터를 업데이트한다. 이렇게 하면 뮤테이터는 절대 fromspace에 있는 흰색 객체를 보지 못한다.
그러다가 fromspace에서 모든 살아있는 객체가 tospace로 복사 완료되면 이때 Flip을 해서 fromspace와 tospace를 개념적으로 뒤집는다.
삼색 조합이 여기 도입되었다7.
- 흰색: fromspace에서 아직 스캔되지 않은 객체.
- 회색: tospace에 있지만 자식을 스캔하지 않은 객체.
- 검은색: tospace에 있고 완전히 스캔된 객체.
참고로 이 당시의 환경은 단일 쓰레드지만 번갈아서 실행하는 (Interleaving) 동시성 환경이 가능하던 때였다. 뮤테이터랑 컬렉터가 동시에 실행되더라도 이 불변식만 지키면 문제가 없다. 다만 Flip 연산은 일종의 transaction이라서 한번에 반영이 되어야 하기 때문에 어쩔 수 없이 프로그램을 멈춰야 했다.
세대 별 컬렉션 (Generational Collection)
1980년대에 많이 주로 쓰이던 언어인 Lisp, Cedar Mesa, Smalltalk-80 같은 언어에는 앞에서 설명한 가비지 컬렉션들이 탑재되어 있었다. 하지만 당시의 제한적인 하드웨어로 인해서 “실시간”을 달성하는 게 쉽지 않았다고 한다. (당시 하드웨어 스펙은 1-3 MIPS, 메모리 1-3MB 수준으로 지금에 비교하면 약 100만배는 느리다.) 예를 들면, Smalltalk-80로 구현된 프로그램이 SUN 머신에서 돌아갈 때 GC로 인해서 1-20분 마다 1-2초 정도의 정지 시간을 겪었고, 몇몇 Lisp 프로그램의 경우 80초마다 4-5초 정도의 정지 시간이 있었다. 이런 긴 정지 시간은 실시간으로 상호작용하는 프로그램을 만들 수 없게 한다.
이 문제를 해결하기 위해서 다양한 연구가 진행되었다. 앞의 점진적 컬렉션들도 그 일부다. 이 중에서 지금까지도, 가비지 컬렉션 뿐만 아니라 수많은 메모리 관리 기법에 커다란 영향을 남긴 것이 바로 Henry Lieberman과 Carl Hewitt의 세대 가설(Generational Hypothesis)이다. 수명이 짧은 객체가 저장 공간 사용량의 상당 부분을 차지하기 때문에 얘네들을 더 빨리 수집하면 가비지 컬렉터를 충분히 최적화하여 실시간으로 상호작용할 수 있다는 것이다. 즉, “대부분의 객체는 빨리 죽는다 (Most objects die young)”8.
세대 가설은 가비지 컬렉션의 패러타임을 완전히 바꿔버렸다. 객체의 수명을 기준으로 컬렉터가 관리하는 힙 메모리를 두 개 이상의 세대로 나누고 각각의 세대마다 가비지 컬렉션 알고리즘을 다르게 적용하여 최적의 성능을 내도록 하는 방향으로 진화가 일어난 것이다. 세대 별 컬렉션의 탄생이었다.
최초의 세대 별 컬렉션은 베이커의 점진적 복사 컬렉션에 먼저 도입되었다. 복사 컬렉션의 메커니즘이 객체의 세대 간 이동과 잘 호환되어 구현이 쉬웠나보다. 무엇보다 복사 컬렉션의 경우 살아있는 객체를 다른 공간으로 옮겨야 해서 살아있는 객체가 적을수록 효율이 좋은데, 세대 가설에 따라 대부분은 빨리 죽을 것이므로, 이 효율성을 극대화시킬 수 있었다.
대부분은 두 개의 세대를 운영한다.
- 첫 번째 세대: 모든 객체가 처음 할당되는 곳이다. 세대 가설에 따라 여기 할당된 객체들은 대부분 살아남지 못하고 수집될 것이다. 언어마다 명칭이 다른데 마이너 힙, 어린 힙, Generation 0, 에덴 공간 등 다양한 재밌는 이름으로 불린다.
- 두 번째 세대: 첫 번째 세대를 살아남는 객체들이 옮겨지는 곳이다. 여기까지 온 객체들은 훨씬 더 오래 살아남는 경향이 있다. 그래서 이 세대에 가비지 컬렉션이 동작하게 되면 첫 번째 세대보다는 수집되는 비율이 적을 수 있다. 메이저 힙, 성숙한 힙, Generation 1, 생존자 공간 등으로 불린다.
세대 가설이 효과적인 이유 중 하나는 객체의 수명 주기를 고려해서 세대마다 서로 다른 컬렉션 알고리즘을 적용할 수 있다는 것이다.
- 첫 번째 세대: 세대 가설에 따라 수많은 객체가 생성되지만 금방 죽는다. 이 특성에 근거해서 많은 언어들은 첫 번째 세대의 힙 메모리에 복사 컬렉션을 도입한다. 복사 컬렉션의 할당은 포인터 주소를 더하기만 하면 되어서 속도가 대단히 빠르고, 메모리 구간이 연속적이라 스캔 속도 역시 빨라서 몇 안되는 살아남은 애들을 다음 세대로 옮기는(promotion) 작업도 효율적이다.
- 두 번째 세대: 세대 가설에 따라 여기까지 살아남은 애들은 오래 살아남을 것이다. 그러므로 정확하고 안전하게 가비지를 수집하는 것이 중요하다. 초기에는 여기도 같은 복사 컬렉션을 도입했지만 현재는 많은 언어들이 마크 스윕 (+컴팩션) 컬렉션을 도입한다.
세 개 이상의 세대를 가진 가장 성공적인 언어는 바로 C#(.NET)이다. 닷넷은 총 세 개의 단계적 세대와 하나의 별도 세대를 관리한다. Generation 0에서 살아남아 Generation 1, Generation 2로 갈수록 살아남은 객체들은 오래 살아남을 것이다. 더 오랜 세대에는 가비지 컬렉션이 호출되는 빈도가 급격히 줄어들게 되고, 따라서 매우 효율적인 실행이 가능하다.
- Generation 0: 첫번째 세대.
- Generation 1: 첫번째 세대를 살아남은 중간 세대. 버퍼 역할을 한다.
- Generation 2: 마지막 세대. 길게 살아남은 객체들이 여기 있다.
- LOH(Large Object Heap): 85KB 이상의 큰 객체는 곧바로 여기에 할당되며 별도로 관리한다.
자바도 공식적으로는 Young Generation과 Old Generation 두 개의 세대를 운영하지만, 실제로는 Young Generation이 세 개의 영역으로 세분화되어 있다.
- 에덴 공간: 첫번째 세대.
- Survivor 0: 첫번째 세대를 살아남은 세대.
- Survivor 1: 역시 첫번째 세대를 살아남은 세대.
에덴 공간에서 살아남은 객체들이 Survivor 0과 1 세대를 번갈아 이동하고 나중에 오래 살아남은 애들은 Old Generation으로 가게 된다.
OCaml은 반면 두 개의 세대를 운영한다.
- 마이너 힙: 첫번째 세대. 앞에서 얘기한 체이니의 복사 컬렉션을 쓴다.
- 메이저 힙: 오래 살아남은 세대. 마크 스윕 컴팩션 컬렉션을 쓴다. 다만 압축이 자주 일어나지는 않는다.
이렇게 두 세대로 메모리를 나누고 나면, 보통은 다음과 같은 순서를 따라 가비지 컬렉션이 동작한다.
- 모든 사소한(trivial) 객체는 첫 번째 세대(이후 마이너 힙으로 표현)에 할당된다.
- 마이너 힙이 꽉 차면 마이너 힙 컬렉션이 촉발되어 마이너 힙에 대한 수집이 시작된다. 보통은 복사 컬렉션이기 때문에 빠르게 가비지가 수집된다. 여기서 살아남은 애들은 두 번째 세대(이후 메이저 힙으로 표현)로 옮겨진다.
- 이후의 사소한 객체들도 모두 마이너 힙에 할당된다.
- 메이저 힙이 꽉 차면 메이저 힙 컬렉션이 일어난다. 보통은 마크 스윕 컬렉션의 변형이기 때문에 앞에서 설명한 것들, 예를 들면 점진적인 STW와 SATB 등의 기법이 적용되어 최대한 효율적으로 수행된다.
따라서 세대 별 컬렉션이 탑재된 언어에서는 워크로드에 따라 이 두 가지 세대의 힙 모두를 조절할 수 있는 파라미터를 잘 튜닝하는 것이 관건이다.
쓰기 배리어 (또?)
세대 별 컬렉션은 사실 거의 독립적인 두 개의 가비지 컬렉터가 거의 독립적인 두 개의 힙을 관리하는 것과 마찬가지이다. 그래서 전에 없던 새로운 엣지 케이스가 생긴다: “메이저 힙의 객체가 마이너 힙의 객체를 가리킬 수 있다”.
이게 왜 문제가 되는지 생각해보자. 예를 들어, 메이저 힙에 오래 살아남은 어떤 객체 A가 있다고 하자. 프로그램이 실행되다가 마이너 힙에 새로운 객체 B를 할당한 후에 A → B 의 참조를 만들었다. 그러면 B는 항상 A롤 통해서만 닿을 수 있는 살아있는 객체가 된다. 근데 마이너 힙 컬렉터는 마이너 힙만 관리하기 때문에 이 A → B 체인을 알 수가 없다. 그래서 이 정보를 모르면 B를 가비지로 판단하고 잘못 수집해버릴 수 있다.
그래서 세대 별 컬렉션은 이를 해결하기 위해 새로운 불변식을 도입한다: “마이너 힙 컬렉션 시에는 메이저 힙에서 마이너 힙으로 가는 모든 참조를 알아야 한다.”
여기에도 “배리어”를 쓴다. 앞에서와 마찬가지로 읽기 배리어와 쓰기 배리어가 있는데, 여기서도 쓰기 배리어에 집중해보자. 점진적 컬렉션의 쓰기 배리어와 목적이 다르다.
- 쓰기 배리어 (점진적 컬렉션): 검은색 → 흰색 참조를 막음
- 쓰기 배리어 (세대 별 컬렉션): 메이저 힙 → 마이너 힙 참조를 추적함
즉, 세대 별 컬렉션에서의 쓰기 배리어는 단순히 세대 간 참조를 막는게 아니라 이 참조들을 모두 추적한다. 메이저 힙에서 마이너 힙으로 가는 모든 포인터를 기억 집합(Remembered Set)이라는 자료구조에 담아두면, 이후 마이너 힙 컬렉션에서 루트 집합과 함께 이 기억 집합을 살펴볼 수 있다. 루트 집합을 확장하는 셈이다.
세대 별 컬렉션의 쓰기 배리어는 점진적 컬렉션의 쓰기 배리어와 마찬가지로 모든 포인터 쓰기 연산을 추적해야 하기 때문에 컴파일러의 도움이 필요하다.
고급 기능들
이렇게 가비지 컬렉션은 자동으로 객체의 메모리를 할당하고, 가비지 여부를 탐지하고, 메모리를 수집해뒀다가 재사용하게 해주지만, 사실 이 방법들은 모두 프로그램의 워크로드 특성에 따라 그 효율이 다를 수 밖에 없다. 그래서 많은 언어들이 워크로드에 맞게 가비지 컬렉션을 튜닝하거나 혹은 가비지 컬렉션의 동작을 고려한 특수한 목적의 기능을 제공한다.
GC 파라미터
많은 언어가 세대 별 컬렉션을 기본으로 탑재하고 있기 때문에, 대부분 마이너 힙과 메이저 힙의 특성이나 각각의 힙에 대한 컬렉션을 조절하는 파라미터를 제공한다. 모든 파라미터를 다룰 순 없으니 여기서는 몇 가지 대표적인 것들만 예로 가져와봤다.
자바는 이른바 Roofline이라고 불리는 파라미터를 제공한다. JVM이 최대로 사용할 수 있는 메모리를 설정할 수 있다. 그러면 프로그램은 정해진 메모리 한도까지만 사용할 수 있고 이걸 넘는 순간 컬렉션이 동작한다. 자바의 이런 접근은 당시의 엔터프라이즈 환경에서는 적합한 것이었다. 그때는 하나의 프로그램이 하나의 머신의 리소스를 다 차지한 채로 무한정 돌면서 사용자의 요청 사항을 처리했으니.
하지만 점차 프로그램의 요구사항이 복잡해지면서 이런 루프라인 파라미터는 튜닝하기가 대단히 까다로워졌다. 당장 프로그램이 실행하면서 얼마나 많은 메모리를 필요로 할지 모르는 경우가 많다.
그래서 OCaml의 경우는 조금 다른 접근을 했다. 메모리의 최대 사용량을 고정하는게 아니라, 메모리를 얼마나 낭비해도 될지를 조절할 수 있는 Space Overhead라는 파라미터를 제공한다. 예를 들어 Space Overhead가 80(기본값)이면 실제로 필요한 메모리의 80%까지 추가로 낭비하는 것이 허락된다. 그래서 프로그램이 실제로 100 만큼의 메모리를 필요로 하더라도 180까지는 GC가 즉시 동작하지 않고 기다려준다.
사실 이외에도 많은 파라미터가 있다. 이건 컴퓨터 공학에서 언제나 있어왔던 트레이드 오프의 일종이다. 정확히는 CPU의 계산과 메모리 사이의 트레이드 오프, 혹은 뮤테이터와 컬렉터 사이의 트레이드 오프로, 메모리를 좀 낭비하되 계산(뮤테이터)을 더 많이 할지, 아니면 메모리를 타이트하게 아끼되(컬렉터) 계산에 필요한 리소스(CPU)를 좀 뺏길지를 결정하는 것이다.
당연히 은총알은 없고 뭐가 더 맞는 접근인지는 프로그램의 워크로드나 프로젝트의 요구사항에 따라 다르다.
- 실시간 시스템: GC로 인한 정지 시간을 최소화하는 것이 중요하다. 그래서 메모리를 좀 낭비하더라도 정지 시간을 최소화 하도록 튜닝한다.
- 서버: 응답 시간의 예측 가능성이 중요하다(P99). 메모리를 좀 낭비하더라도 최악의 정지 시간이 통제 가능할 정도여야 한다.
- 임베디드 시스템: 리소스가 제한적인 경우가 많아서 메모리 사용량을 최소화해야 한다. 뮤테이터가 계산을 좀 덜 하더라도 컬렉터한테 양보해줘야 한다.
약한 포인터 (Weak Pointer)
가비지 컬렉터가 장착된 언어는 약한 포인터라는 기능을 제공하는 경우가 많다. 약한 포인터, 또는 약한 참조(Weak Reference)는 컬렉터와 상호작용하는 특수한 포인터로, 이름 그대로 힘이 약해서 (…) 얘가 가리키는 메모리는 컬렉터가 회수하는 걸 막지 못해 언제든지 회수당할 수 있다. 즉, 객체의 생명주기에 영향을 주지 않는다.
그럼 이걸 어디다 쓸 수 있을까? 약한 포인터의 활용은 가비지 컬렉션의 종류에 따라서 조금 다르다.
레퍼런스 카운팅에서
약한 포인터는 원래 레퍼런스 카운팅의 순환 참조 문제를 부분적으로 해결하기 위한 도구로 탄생했다. 두 객체 A와 B가 있을 때 A → B, B → A 방향으로 순환 참조가 일어날 수 있는데, 이때 B → A를 약한 참조로 바꾸면 올바르게 메모리를 회수할 수 있게 된다.
예를 들어, 더블 링크드 리스트에서 next 포인터는 강한 참조로, prev 포인터는 약한 참조로 가리키면 순환 참조를 막을 수 있다. 하지만 이 방법은 프로그래머가 미리 순환 참조를 예측하고 설계 단계에서 약한 포인터를 직접 추가해야 하는 번거로움이 있다.
트레이싱 컬렉션에서
트레이싱 컬렉션에서는 주로 캐싱 및 메모이제이션에 활용된다. 캐싱은 성능을 위해서 데이터를 잠깐만 가지고 있다가 메모리가 부족하면 얼마든지 버려도 된다. 그래서 캐싱할 데이터는 약한 포인터로 갖고 있는게 적절하다.
그런데 실제로 약한 포인터로 캐싱을 구현하면 너무 약해서(?) 컬렉터가 얘네를 너무 빠르게 수집해버릴 수 있는데, 이러면 캐싱 효율이 떨어진다. 그래서 보통 캐싱을 위해서는 조금 덜 약한(?) 포인터를 제공하기도 한다.
예를 들면, 자바에서는 진짜 약한 포인터인 WeakReference가 있긴 하지만, 캐싱을 구현할 때에는 좀 덜 약한 포인터인 SoftReference를 쓴다. SoftReference는 메모리가 충분할 때에는 유지되다가 메모리가 정말 부족할 때에만 수집된다.
종료 처리 (Finalisation)
가비지 컬렉션은 메모리 관리를 자동화해주지만 메모리가 아닌 다른 리소스, 예를 들어, 파일 핸들, 네트워크 소켓, 데이터베이스 커넥션과 같은 외부 시스템과 연동된 리소스들은 관리해주지 못한다. 이런 리소스와 연결된 프록시 객체를 다 쓰고 나면 단순히 메모리를 수집하기 전에 리소스 핸들을 닫는 “정리 작업”을 해줘야 한다.
가비지 컬렉션 위에서 이 정리 작업을 자동으로 해주기 위해 탄생한 것이 바로 종료 처리 혹은 종료자(Finaliser)이다. 어떤 객체가 “거의 수집 가능(Almost Collectable)”하다고 판단되면 컬렉터는 그 객체를 수집하기 전에 뮤테이터한테 이걸 알려준다. 그러면 뮤테이터는 그 객체와 연관된 종료 처리 작업(보통 함수)을 진행해서 외부 리소스도 올바르게 관리할 수 있다.
근데… 이게 생각보다 되게 까다롭다.
실행 시점이 불확실함
레퍼런스 카운팅에서는 참조 횟수가 0이 되면 가비지이니 비교적 “거의 수집 가능” 시점이 명확하다. 하지만, 트레이싱 컬렉션은 다르다. 객체가 정말로 가비지가 되는 시점과 컬렉터가 마킹 단계에서 이 사실을 발견하는 시점 사이에는 시차가 있다. 심지어 일부 가비지는 프로그램이 끝날 때까지 수집되지 않을 수도 있다. 그래서 종료 처리가 언제 적절하게 실행될지 확실하게 보장할 수 있는 방법이 없다.
올바른 실행 순서가 뭔지 모름
종료 처리를 올바른 순서로 실행하는 것도 골치 아프다. 직관적으로는 위상정렬을 통해 의존성이 없는 객체부터 종료 처리를 실행하는게 맞을 것 같다. 하지만 이론적으로는 객체들 사이에 싸이클이 있을 수 있어서 위상정렬이 불가능한 경우가 있다.
그럼 아예 랜덤한 순서로 실행하는 건 어떨까? 이러면 구현은 간단해지겠지만 어떤 종료 처리 A가 참조하는 다른 객체가 먼저 종료 처리 되어서 Use After Free를 일으킬 수 있다. 즉, 종료 처리 작성을 엄청나게 어렵게 만든다.
객체 부활 (Object Resurrection)
더 큰 문제는 종료 처리가 죽은 객체를 되살릴 수 있다는 것이다! “거의 수집 가능”한 객체도 다른 객체에 접근할 수 있는데, 종료 처리 코드가 자기 자신 (예를 들어 self 혹은 this)을 전역 변수나 정적 데이터 구조에 저장하면 스스로를 부활시키는 꼴이 된다. 다음 파이썬 코드가 그 예시다.
global_reference = []
class Zombie:
def __del__(self):
global_reference.append(self)
obj = Zombie()
del obj
이걸 감지하려면 쓰기 배리어를 강제해야 하는데, 그렇다고 이게 항상 가능한 것도 아니다. 그리고 객체의 부활 가능성만으로도 가비지 컬렉션이 훨씬 복잡해지고 느려진다. 종료 처리를 감안하여 어떤 객체를 올바르게 수집하려면 최소 2번의 컬렉션이 필요하게 되기 때문이다.
초기 구현
초기에는 약한 포인터를 가지고 종료 처리를 구현했다. 기본 아이디어는 다음과 같다.
- 종료 처리가 필요한 객체가 약한 참조를 생성한다.
- 생성한 약한 참조 객체에 종료 처리 함수(콜백)을 연결한다.
- 컬렉터가 마킹 단계에서 객체를 수집할 때,
- 먼저 약한 참조를 따라가지 않고도 닿을 수 있는 객체를 모두 찾는다.
- 위에서 못찾았지만 약한 참조로만 닿을 수 있는 객체를 찾는다. 이들이 바로 “거의 수집 가능”한 객체들이다.
- “거의 수집 가능”한 객체들에 연결된 콜백을 실행한다.
파이썬의 weakref.finalize가 이 방식을 사용한다.
import weakref
def cleanup(resource_id):
close(resource_id)
class Resource:
def __init__(self, resource_id):
self._finalizer = weakref.finalize(
self, # 감시할 객체
cleanup, # 정리 함수
resource_id, # 정리 함수에 전달할 파라미터
)
이렇게하면 죽은 객체가 다시 부활하는 것을 막을 수 있다. 하지만 그럼에도 여전히 다른 한계가 남아있다.
결론적으로 이런 여러가지 이유로 현대의 프로그래밍 언어들은 종료 처리 기능이 있긴 하지만 종료 처리 사용을 지양하도록 하는 편이다. 예를 들어 파이썬은 종료 처리 쓰지 말고 명시적으로 리소스를 관리하도록 (예: with) 장려하는 추세다. 역시 호환성은 어렵다.
이페메론 (Ephemeron)
이페메론은 약한 참조를 조금 더 일반화하고 “거의 수집 가능함”을 재정의한다. 에피메론? 아니면 발음 기호대로 읽으면 이페머른? 정도 되는 것 같은데, 그리스어로 “하루만 사는” 또는 “덧없는” 뜻하는 Ephemeros에서 유래했다. Ephemeros는 하루살이의 어원이다. 여기서 이걸 하루살이라고 부를 순 없으니 이페메론 정도로 부르겠다.
이페메론은 논리적으로는 키-값 쌍을 담은 일종의 해시 테이블 (혹은 딕셔너리) 이다.
- 이페메론 키: 약한 포인터처럼 동작한다. 키가 가리키는 객체가 다른 곳에서 쓰이지 않으면 이는 곧 수집될 수 있다.
- 이페메론 값: 강한 포인터이지만, 키가 살아있을 때에만 유효하다. 즉, 키가 수집되면 거기 묶인 값도 같이 수집된다. 그리고 이페메론 값이 다른 이페메론 키를 참조하더라도 이는 약한 포인터로 취급한다. 이것 덕분에 값이 키를 참조하는 순환이 있어도 메모리 누수가 발생하지 않는다.
실제 구현에서 이페메론은 가비지 컬렉터에 의해 특수하게 처리된다.
- 일단 루트 집합에서부터 강한 참조만 따라가서 마킹하고 이페메론은 건너뛴다.
- 각 이페메론의 키가 1에 의해 마킹되었는지 확인한다. 만약 마킹되었다면, 그 값도 마킹한다 (이때 이 값이 다른 키를 참조해도 문제없다). 키가 마킹되지 않았다면, 연결된 키와 값 모두 수집 후보에 올린다.
- Fix Point에 도달할 때까지 2번을 반복한다.
이페메론은 두 개의 연결된 문제를 해결하기 위해서 도입된 데이터 구조다. 하나는 좀더 정확한 종료 처리다. 이페메론을 활용하면 어떤 객체가 수집되기 직전에 알림을 줄 수 있다. 다른 하나는 속성 테이블(Property Table)이라고 불리는 데이터구조다. 보통 이런 속성 테이블은 키-값 쌍을 담은 딕셔너리로 구현되는데, 속성 테이블에 속한 값이 속성 테이블에 속한 다른 키를 가리키는 경우가 많다. 예를 들면 속성 간의 계층을 표현하기 위해서 owner라는 속성 필드가 다른 속성(키)을 가리킬 수 있다. 이페메론이 아니라면 메모리 누수가 나기 십상이지만, 이페메론의 특수한 시맨틱 덕분에 속성 테이블 구현이 프로그래밍 언어 수준에서 가능해진다.
하지만, 이페메론도 종료 처리의 근본적인 문제들을 모두 해결하지는 못한다. 여전히 언제 실행될지를 보장해주진 않고, 컬렉터가 이페메론을 특별하게 처리해줘야 해서 오버헤드가 생긴다. 또, 구현이 어려워서 버그가 생기기 쉽다.
재밌는 사실들
존 매커시의 생각
1959년 존 매커시가 Lisp에 가비지 컬렉션을 구현했을 당시 하드웨어 환경은 지금과 비교하면 엄청나게 열악했다. 메모리가 32KB 수준이었다. MB도 아니고 KB다. 그래서 당시 Lisp의 가비지 컬렉션은 상당히 느린 편이었고, 존 매커시도 이걸 약간 임시 방편같은 느낌으로 생각했다고 한다. 시간이 흐르면 다른 연구자들과 엔지니어들이 더 나은 방법을 찾을 것이라고 믿었던 것이다. 하지만 60년도 더 지난 지금, 오히려 많은 현대의 프로그래밍 언어에서 가비지 컬렉션은 핵심 기능으로 자리 잡은 사실이 재밌다.
가비지 컬렉션을 위한 하드웨어
가비지 컬렉션은 굉장히 오랜 세월 여러가지 언어에서 연구되고 개발되어 왔다. 그러다보니 정말 다양한 접근이 시도되었는데 그 중 하나는 바로 가비지 컬렉션을 위한 특수 하드웨어가 있었다는 것이다. 1980년대에 있었던 특수 목적 컴퓨터인 Symbolics나 TI Explorer는 “Lisp 머신”(진짜 기계)였는데, 트레이싱 컬렉션의 쓰기 배리어 연산을 효율적으로 하기 위한 하드웨어 연산이 지원되는 전용 FPGA가 달려있었다. 그래서 메모리 쓰기 연산이 발생하면 자동으로 쓰기 배리어 로직을 적용해서 기록했다고 한다.
당시에는 이런 특수한 하드웨어가 인공지능 연구에 필수적이라고 생각했었지만 이후에 PC의 성능이 급격하게 좋아지면서 경제성이 안나와서 금방 단종되고 말았다.
듀얼 (Duality)
사실 레퍼런스 카운팅이랑 트레이싱 컬렉션은 수학적으로 듀얼이다!
수학에는 듀얼이라는 개념이 있다. 나는 수학은 잘 모르기 때문에 이걸 정확하게 설명할 자신은 없어서 클로드에게 물어봤다. 일단 듀얼은 개념, 정리, 수학적 구조를 다른 개념, 정리, 구조로 일대일 대응시키는 원리인데, 핵심은 다음 세 가지다.
- 어떤 변환을 두 번 적용하면 원래 것으로 돌아온다. (Involution)
- 두 개념이 대칭적인 관계를 가지며 하나의 관점에서 성립하는 것이 다른 관점에서도 대응되는 형태로 성립한다.
- 단순히 같은 것이 아니라 역 또는 보안 관계에 있는 개념들의 쌍이다.
이 관점에서 레퍼런스 카운팅과 트레이싱 컬렉션을 다시 바라볼 수 있다.
- 트레이싱 컬렉션: 루트 집합에서 부터 시작해서, 살아있는 객체를 추적한다.
- 레퍼런스 카운팅: 안티-루트 집합(즉, 루트 집합이 아닌 모든 객체들)에서 부터 시작해서, 죽은 객체를 추적한다.
트레이싱 컬렉션은 “무엇이 여전히 쓰이고 있는지”를 추적하는 것이고, 레퍼런스 카운팅은 “무엇이 더이상 안쓰이는지”를 추적하는 것이다. 뭔가 직관적으로 서로 연관이 있을 것이라고 생각은 했는데 수학적으로 듀얼이라는 관계에 있다는 사실이 놀랍다. 좀더 엄밀한 수학적인 증명은 A Unified Theory of Garbage Collection by David F. Bacon et. al (IBM Watson)을 참조하여 이해를 시도해보자.
비용
그래서 가비지 컬렉션이 장착된 언어는 수동으로 메모리 관리하는 언어에 비해서 얼마나 (비)효율적일까? 쉽게 답할 수 없는 질문이다. 가비지 컬렉션만의 비용을 측정하는 일은 엄청나게 어렵다. 당장 같은 언어로 구현된 논리적으로 같은 문제를 푸는 서로 다른 알고리즘을 비교하는 것도 어려운 문제인데, 메모리 관리 방식이 서로 다른 두 언어를 비교하는 일에는 방해하는 요소들(Confounding Factors)이 너무 많다. 예를 들어, C언어와 OCaml을 비교하려고 하면 다음과 같은 것들을 고려해야 한다.
- 메모리 레이아웃: 논리적으로 같은 데이터 구조를 표현하더라도, 언어마다 데이터를 표현하는 메모리 레이아웃이 다르다. C에서는 64비트 정수가 곧바로 표현되지만 OCaml에서 64비트 정수를 표현하려면 박싱된 정수를 써야하거나 아니면 박싱안된 63비트 짜리 정수를 써야 한다. 구조체로 들어가면 차이는 더욱 심각해진다. 논리적으로 같은 값이라도 메모리에 배열되는 방식이 다르기 때문에 지역성에도 큰 차이가 있어 효율도 다르다. 이걸 가비지 컬렉션의 비용으로 봐야할까, 아니면 이걸 완전히 별개로 생각하고 측정해야할까?
- 배열 바운드 체크: OCaml은 모든 배열 연산에 기본적으로 바운드 체크를 하기 때문에 상대적으로 안전한 대신 오버헤드가 숨어있다.
- 함수 호출: C는 표준적인 함수 호출 컨벤션을 따르는 반면, 함수형 언어인 OCaml에서의 클로저는 오버헤드가 있는데, 이는 클로저 역시 가비지 컬렉션에 의해 수집될 수 있는 대상이기 때문이다. 함수 호출 방식이 서로 달라서 발생하는 비용을 어떻게 측정하고 비교할 수 있을까? 이것 역시 가비지 컬렉션의 숨겨진 비용일까?
- 컴파일러 최적화: 수십년간 수많은 엔지니어와 연구자들이 최적화한 GCC/Clang에 비해서 OCaml의 최적화는 부족한 부분이 있을 수 있다. 이걸 어떻게 동일선 상에 놓고 비교할 수 있을까?
- 쓰기 배리어의 오버헤드: OCaml의 세대 별 컬렉션의 정확성을 위해 도입된 쓰기 배리어는 모든 포인터 쓰기 연산에 추가적인 조건을 검사한다. 하지만 실제로 OCaml 프로파일러로 GC가 동작하는 시간(즉, 마이너/메이저 힙 컬렉션)을 측정할 때에는 이 오버헤드가 포함되지 않는다.
- 메모리 할당자: OCaml은 앞서 설명했던 가비지 컬렉션이 제공하는 할당 방식을 쓸 수 밖에 없지만, C에는 다양하게 최적화된 할당자들이 많다. 예를 들면, tcmalloc, jemalloc 등이 있다. 이들을 모두 같은 “메모리 할당자”라고 볼 수 있을까?
- 튜닝 파라미터: OCaml의
Gc모듈에는 가비지 컬렉션의 동작을 미세 조정할 수 있는 다양한 파라미터가 있다. 그래서 특정 워크로드마다 이 값을 튜닝해서 최적의 성능과 메모리 효율 사이에서 원하는 것을 얻을 수 있다. C 프로그램과 비교할 때 어떤 파라미터 값을 기준으로 비교해야 의미가 있을까?
당장 가비지 컬렉션에 대해서 조금 이해한 내가 생각나는 요소들만 이 정도다. 애초에 공정한 비교는 불가능한 것일지도 모르겠다.
또 분량 조절에 실패하고 엄청나게 긴 글을 써버리고 말았다. 분명 마크 스윕 컬렉션 알고리즘 얘기를 끄적거리고 있었는데 어쩌다가 이렇게 길어진거지… 아무튼 여기까지는 싱글 프로세서에서의 가비지 컬렉션 얘기였다. 다음에는 좀더 구체적으로 OCaml에서 어떤 식으로 구현되어 있는지, 그리고 2026년 현재 가장 최신의 병렬 가비지 컬렉션은 어떤 방식으로 동작하는지 살펴보고 싶다.
글을 적는데 참고한 것들:
- Memory Management with Stephen Dolan
- Uniprocessor Garbage Collection Techniques by Paul R. Wilson (CMU)
- A Real-Time Garbage Collector Based on the Lifetimes of Objects by Henry Lieberman and Carl Hewitt
- Generation Scavenging: A Non-disruptive High Performance Storage Reclamation Algorithm by David Ungar
- A Unified Theory of Garbage Collection by David F. Bacon et. al (IBM Watson)
- GC FAG – draft
- MemFix: Static Analysis-Based Repair of Memory Deallocation Errors for C
-
컴퓨터 과학의 한계를 증명한 정리 중 하나인 라이스의 정리에 따르면, 프로그램의 모든 non-trivial semantic 성질은 결정 불가능하다. 그래서 Rust의 경우 언어의 표현력을 제한해서 이 문제를 결정 가능한 수준으로 축소해서 풀고, 컴파일러가 추론이 불가능하면 프로그래머에게 명시적인 라이프타임 어노테이션을 요구한다. ↩
-
엉클 밥의 “읽기와 쓰이게 소요되는 시간의 비율은 10:1을 훨씬 상회한다” 라던지, 귀도 반 로썸의 “코드는 쓰이는 것보다 더 자주 읽힌다” 라던지. ↩
-
정확히는, 이렇게 찾은 객체들을 전체 메모리에서 빼고 남은 메모리를 가비지로 간주할 수 있다. ↩
-
적은 수의 비트만을 사용해 참조 횟수에 대한 정확도를 희생해서 더 보수적인 근사치를 계산하는 최적화 방법이 연구되기도 했다. ↩
-
하지만 레퍼런스 카운팅 “알고리즘” 자체는 유용하게 널리 쓰이는 편이다. 예를 들면, C++의 스마트 포인터나 유니크 포인터가 그러하고, 혹은 정말로 이런 식으로 밖에 관리할 수 없는 외부 리소스들, 예를 들어 파일 식별자에 대해서 자동으로
open/close쌍을 호출할 때 쓰이기도 한다. ↩ -
사실 이 문제는 마크 스윕에만 한정된 문제는 아니고 대부분의 힙 관리 방법에 공통된 문제다. ↩
-
삼색 조합 자체는 당시 다익스트라 등에 의해 처음으로 발표되었다. ↩
-
이후 David Ungar의 후속 연구에 의하면, 실제 프로그램의 메모리 사용 패턴을 분석해보니 언어나 프로그램에 상관없이 대부분(80-98%)의 객체는 잠깐만 살아 있다가 사라지고 일부 객체들만이 오래 살아남는고 한다. ↩